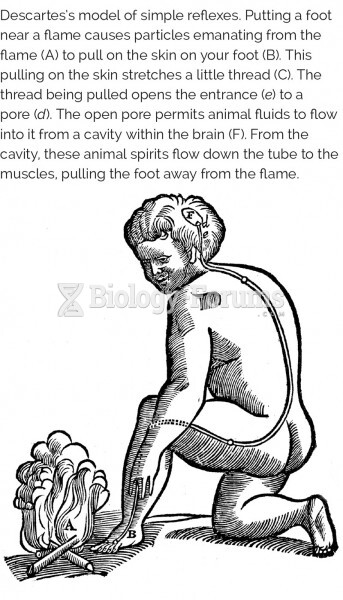
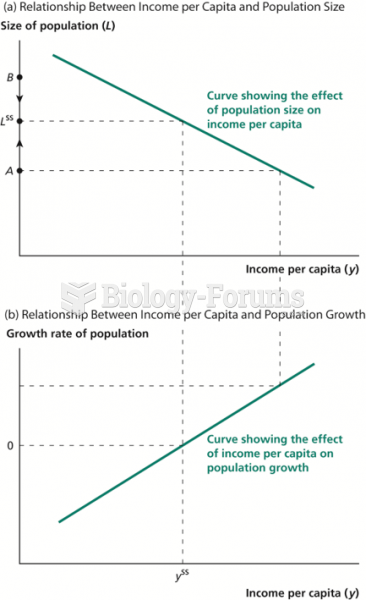
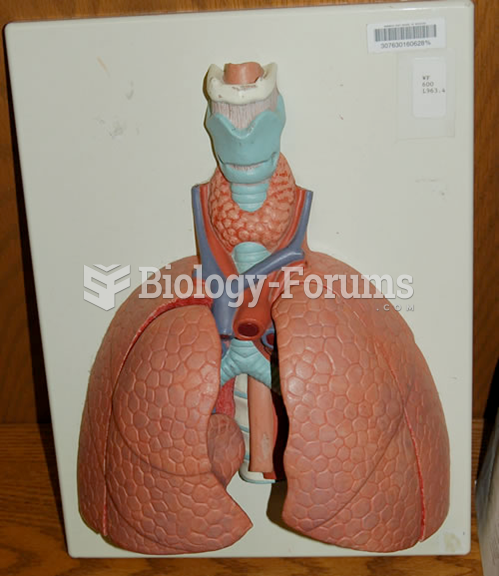
|
|
|
Explore
Post your homework questions and get free online help from our incredible volunteers
1381 People Browsing
131 Signed Up Today
Your Opinion
It's sore throat season, why does my mucus have red spots?
Courses by Biology Forums
The Toxic Skin and Fungi Defense
Bonobos, Chimpanzees, and the 98% DNA Link
Strange Ingredients Lurking in Doritos Chips
|
 Quick Reply
Quick Reply